Unlike RDBMS databases, Cassandra will not do in place update, delete or any modification, deletes are also kind of inserts and it will follow the rule of Last Write Wins(LWW). The data is always written to the immutable files called SSTABLES, In the context of Cassandra, a tombstone is specific data stored alongside standard data. A delete does nothing more than insert a tombstone.
Tombstones will not be cleared until certain time, which can controlled by the parameter gc_grace_seconds in cassandra.yaml file
Why tombstones will not be cleared until certain time?
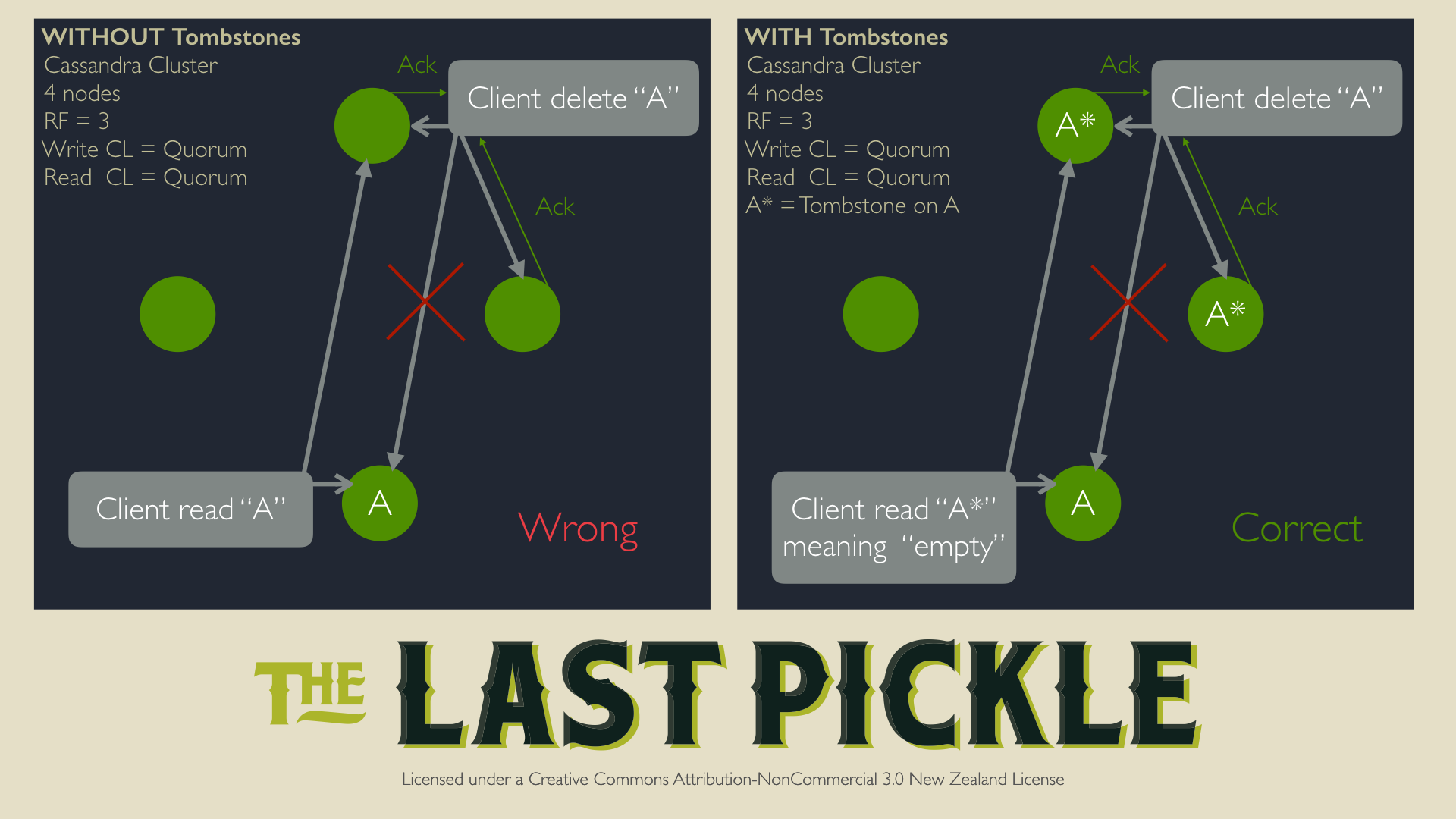
As it is distributed database, suppose a delete happens with a Replication Factor of 3 and Consistency Quorum, before acknowledging to the client node, Cassandra will make sure that data is written to 2 out of 3 nodes, however as RF is 3 the data will be written to 3rd node also eventually. Even if the 3rd node is down by the time deletes were happening, Cassandra will consider this as successful transaction. Because it satisfied the consistency level. So once the third node is up there will be no deleted data in that node. So if the user try to read, the next read involving that node will be an ambiguous read since there is no way to determine what is correct: return an empty response or return the data? Cassandra would always consider that returning the data is the correct thing to do, so deletes would often lead to reappearing data, called “zombie” or “ghost” and their behavior would be unpredictable.
So as a workaround for this Cassandra introduced a parameter gc_grace_period, the default value for this parameter is 1064000(10 days), when there are huge deletes it is always good to run repair before the gc_grace_period.
Tombstones will cause performance issues, Cassandra will read the tombstones while reading the actual data. There are two parameters in cassandra.yaml that will help to log and abort when the query exceeds scanning certain no. of tomstones.
tombstone_warn_threshold (default: 1000): if the number of tombstones scanned by a query exceeds this number Cassandra will log a warning in system.log
(which will likely be propagating to your monitoring system and send you an alert).
tombstone_failure_threshold (default: 100000): if the number of tombstones scanned by a query exceeds this number Cassandra will abort the query.
The is a mechanism to prevent one or more nodes from running out of memory and crashing.
Ways to clear tombstones
Tombstones will be cleaned regularly, over time, by compactions(Please verify compaction article to know when will a compaction triggers and about types of compaction). In some cases because of shadowed data or due to a bulk delete, tombstones are not cleaned quickly enough, and can cause queries to fail (because of tombstone_fail_threshold) or nodes to be overloaded (because of the processing overhead). In these cases, there are a few ways to clean them aggressively (at the cost of using more system resources while the cleaning is being done).
A major compaction on the table, one node at a time will compact all the sstables together into one big sstable, So in the case of SizeTieredCompactionStrategy, you can use the ‘-s’ option when doing the compaction, but with TimeWindowCompaction -s will not help and all the sstables will be combined to one big sstable, so it is advised to then stop DSE and use sstablesplit to split the table into manageably-sized sstables.
A minor compaction( less invasive approach) is to tune the compaction sub-properties for the table’s compaction strategy, tombstone_threshold(Default value is 0.2, If the ratio exceeds this limit, Cassandra starts compaction on that table alone, to purge the tombstones) and tombstone_compaction_interval(Default value is 1 day(86400). The minimum number of seconds after an SSTable is created before Cassandra considers the SSTable for tombstone compaction. Cassandra performs tombstone compaction on an SSTable if the table exceeds the tombstone_threshold ratio) . These parameters can altered in table definition to clean tombstones more aggressively. Also, in SizeTieredCompactionStrategy, the min_threshold(the default value is 4, The minimum number of SSTables to trigger a minor compaction) for compaction can be reduced to compact sstables more quickly.
One more approach is to use “nodetool garbagecollect” then either perform single-sstable compactions on the sstables, or run garbagecollect a second time, to clean out partition-level tombstones. On the first run, garbagecollect clears out the deleted (or “shadowed”) data that tombstones mark. On a second run, or during later compactions, if there’s a tombstone that deletes an entire partition, and that partition is not in other sstables, the tombstone can be safely cleaned out. (For tombstones that shadow individual rows or cells, it’s not as easy to drop them, and they won’t be cleaned out by garbagecollect or a single-sstable compaction.)
‘nodetool garbagecollect’ clears deleted data from sstables. —–What is actually a deleted data ?
suppose you insert bunch of rows and do nodetool flush, again you delete few records of the same inserted rows and you flush again,
now you have 2 sstables, one with tombstones and other with data that is shadowed by tombstones.
Garbagecollect actually helps to clear deleted data in first sstable that is no longer needed because it is shadowed by tombstones in the second sstable.
Which in turn helps to clear tombstones in second sstable. “nodetool garbagecollect” does not generally drop the tombstones even after gc_grace_seconds,
it can be used to reclaim space, or to make it more likely that tombstones will be dropped in subsequent compactions.
{kind=link}